Data network effects for an artificial intelligence startup

This article was originally published in the Towards Data Science publication on Medium, and scored 6.1K views (archived).
The artificial intelligence (AI) ecosystem matures and it is becoming increasingly difficult to impress customers, investors, and potential acquirers by just attaching an .ai domain to whatever you are doing. Therefore, the significance of building a defensible business model in the long run becomes obvious.
In this post, I explore how an AI startup may unlock various data network effects. I explain why it’s important to go beyond the conventional definition of data network effects as a way to collect data from clients for the sake of improving your model/product.
Data network effect — what’s wrong with using it to collect more data?
One of widely cited ways of building moats around an AI business is data network effects, defined as ‘…a property of a product that improves with the more data it has available, due to emergent relationships between segments of the data’. Data network effects is a particular manifestation of a wider phenomenon of network effects, that is seen when ‘… more usage of the product by any user increases the product’s value for other users (and sometimes all users)’. Data network effects are associated, among other things, with improvement of a product via data collected from its users.
Given the importance of data for any AI startup, there is no surprise that data network effects are considered a relevant moat. Data that is required to train a model is hard to get, and if it’s biased, you’re in trouble. So trying to collect as much data as possible and improve a product based on it, seems to be a very good idea. And it is, to some extent. However, the power of data network effects that are built only around data collection and product improvement should not be overestimated and alternative ways to create data network effects should be explored. In order to start distinguishing various types of data network effects, let’s label the one described above as the data collection network effect.
Why having data collection network effects may not be enough for success?Amoung other things, it’s because of the asymmetrical relationship between product usage and useful new data generated. For example, just a fraction of users write reviews on Yelp, i.e. contribute to Yelp’s data collection network effecs.
Sometimes data collection network effects are asymptotic, meaning that the 5th review on Yelp adds much more valuable than the 30th. At some point value of new data goes down, either to users directly (one can hardly read 50 reviews about one cafe) or to product/model development (sometimes better effects come from increasing complexity of a model rather than from pouring more data).
Other challenges with data collection network effects are associated with data availability. First, data can be stolen/copied. Second, its availability is growing. For example, in 2017 eight new public object detection and recognition datasets were added, while only four in 2016. Moreover, there is synthetic data, that helps startups to compete even with data rich giants. The wider availability of data and tools to process/label it makes the data collection network effect less appealing, as it takes less time to disrupt the first-mover advantage of someone with a labelled dataset.
All above being said, I am not arguing that data collection is not something an AI startup should master, as proprietary data is still a moat. It’s also a kind of an insurance policy, that helps a startup to remain attractive to investors/acquirers even if everything goes wrong.
What is important to stress is that the data collection network effect hardly works well for all AI businesses. For instance, it fits well to someone like Waze, where every user contributes valuable data (no asymmetry and not asymptotic) in real time (less harm if Waze’s data is copied/made public). But other types of businesses should think about alternative types of data network effects.
A wider view on data network effects — share more data with your network
New types of data network effects may come from building a wider network of customers and partners around an AI startup and data sharing within that networks. It’s known that sometimes ‘…the network is what provides the majority of the value, not the app or website itself — which explains why marketplaces products like eBay and Craigslist can afford to look essentially unchanged after 16 years’.
One may find extensive literature on data collection network effects (dubbed just ‘data network effects’, or ‘data flywheel’), for example here, here, here, here, and here. However, applications of network effects to data beyond its collection and direct use to improve a model/product, do not seem to be well covered.
A few authors develop the idea of data sharing, but non goes into operational details. For example, Gil Dibner comes up with the concept of ‘System of Network Intelligence’, that works ‘across various parties in a supply chain’ and ‘creates incremental value by sharing intelligence across customers’, therefore data is not only aggregated for the sake of improving a model, but is shared across the supply chain. The idea of data sharing is also explored by Open Data Institute (ODI) and its framework of five business models, differentiated based on degree of data and algorithm openness. The fundamental role of data sharing in the progress of AI ecosystem is coveredby Nik Bostrom, for example.
How to build a network?
Inspired by the literature quoted above, one needs to shift from thinking about an AI startup only as a product (that is improved by data collected from customers/users) to thinking about it as a network, that ignites/manages various types of data exchanges between various types of participants. Below, based on literature on network effects and an analysis of business models behind various AI startups, I explore how to build a data network around an AI startup and what kind of exchanges to launch there.
Participants of an AI startup’s network may widely be divided in two groups:
1. Customers/users, those who directly benefit from a product and generate data that underpins the product;
2. Entities that interact with startups’ customers across their respective value/supply chains. These entities can also benefit from data generated by an AI startup customers. For instance, if an AI startup develops an automation solution for farmers, then those who manufacture fertilisers and buy farmer’s produce may be considered participants of its network.
Therefore, an AI startup may use two directions to build data network effects, namely:
1. Horizontally, by helping customers to interact with each other and creating direct network effects, ‘…when an additional participant makes other participants of the same sort better off’;
2. Vertically, by connecting customers with other elements of their value/supply chains and creating indirect network effects, ‘…when an additional participant of one type increases the value that participants of another type get’.
Three kinds of data exchanges
When directions of data exchanges are understood, the question arise what these exchanges are. By exploring hundreds of AI startups, within as well as outside of our portfolio, I can highlight three types of data exchanges, based on their purpose:
1. To gain insights;
2. To support transactions;
3. To integrate processes.
Sharing insights, usually in an indirect manner, across the network is one way of data exchange that is based on data collected from an AI startup’s clients and adds value on top of the product each of them use.
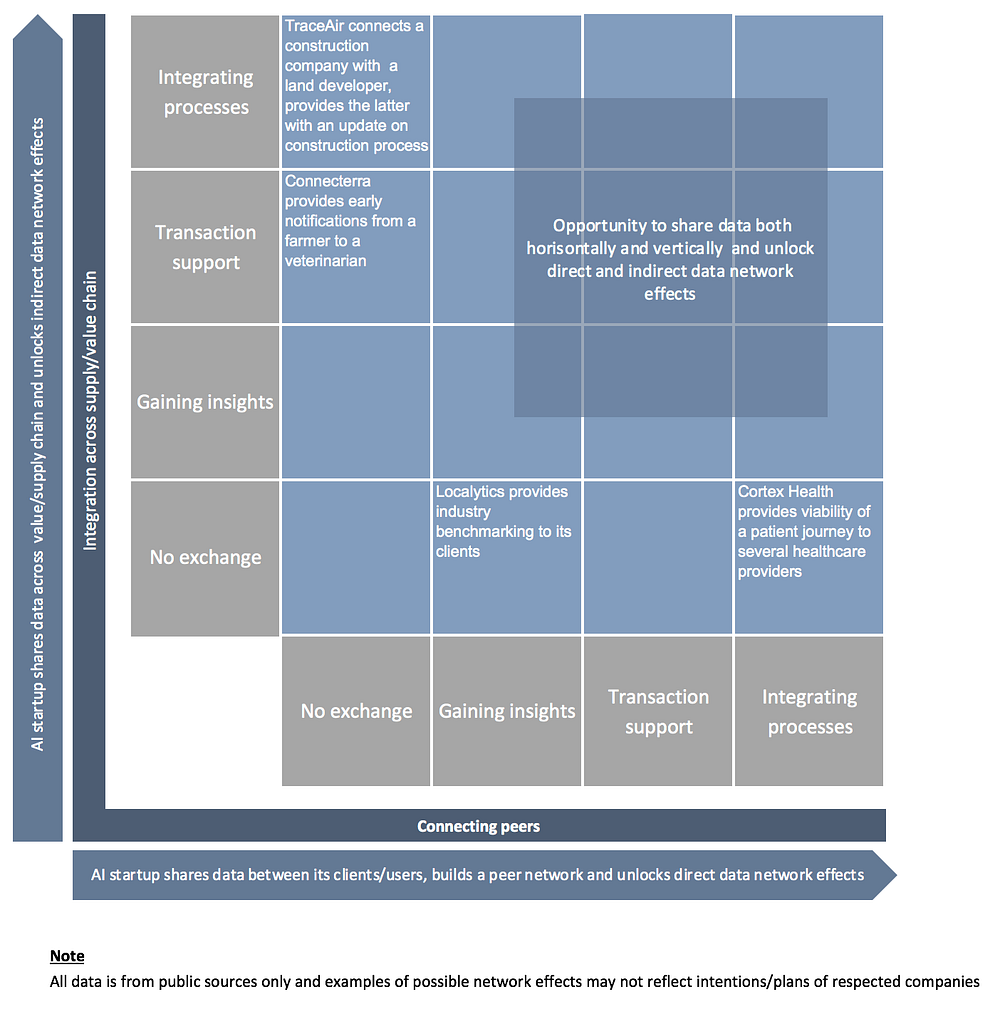
For instance*, Localytics, a mobile app marketing company, uses machine learning to help customers to move ‘… from passively collecting data on in-app activity to identifying key behaviors that improve conversions’. It also offers summary stats and industry benchmarking, helping clients, to some extent, to learn from the market. Localytics harnesses a direct network effect, because as more clients use its core product, the better insights each of them gets about a wider market and the competitive landscape.
Also, an AI startup may use data gained from its clients not only to improve the core product, but also to allow clients to transact better with other participants of their value chain.
For example, a software company Connecterra collects and analyses data from a dairy farm to help a farmer. At the same time, it also opens the platform for veterinarians and feed companies who ‘…see it as a platform to interact with the farmer in a much better way. They can see what is happening on the farm by using the app. If needed, the veterinarian can also get alerts’. Without becoming a veterinary marketplace, Connecterra helps two elements of a value chain (farmers and veterinarians) to transact by sending advance notifications. Connecterra harnesses indirect data network effects, as veterinarians benefit from more farmers being on a platform.
Usually, a certain degree of integration between various elements of a value chain is required. Therefore, an AI startup may not only serve one of the elements directly, but via data exchange it may improve integration of this element with others.
For example, TraceAair uses drone imagery not only to help construction contractors to reduce the cost by moving less dirt twice, but also to share the progress on a site with land developers, allowing them to ‘be on top of the site balance, finish the project on time and save on the contingency budget’. In that setup, land developers benefit from more contractors joining the platform, and TraceAir harnesses an indirect data network effect.
Another example of building an AI product that improves integration across a value chain is Cotrtex Health, which learns trends and predicts patient negative outcomes, and then alerts an appropriate healthcare provider to take certain action. The Cortex network is built around ‘…the idea that patient outcomes can be improved by sharing visibility of a patient’s status with all the accountable healthcare providers, throughout the entire episode of care…’. Note, that this kind of integration goes much beyond sharing data for transactional purposes.
Three types of data exchanges each applied horizontally and/or vertically provide an AI startup with six new opportunities for data network effects (see the data network effects matrix below). The foundation for these new data network effects is the ability to make data useful by directly/indirectly sharing it across the network, whereas more well-known data network effects (data collection network effects) are based primarily on scarcity of data and challenges associated with collecting it. These new data network effects align well with the concept of the platform and the idea that in the twenty-first century ‘…the supply chain is no longer the central aggregator of business value. What a company owns matters less than what it can connect’.
As AI ecosystem matures and the availability of data increases, AI startups become more incentivised to transform themselves into platforms that serve complex networks sprawling within and across multiple value/supply chains.
***
Many thanks to Yuri Burov and Valery Komissarov for reviewing early drafts of this post. Kudos to Matt Turck, Gil Dibner, bradford cross, NFX, and others whose work helped me to come up with this article.
Disclosure: TraceAir and Connecterra, that are mentioned in the article, are portfolio companies of Sistema_VC, a fund where Peter is a Venture Partner.
***
Data network effects matrix
Corrections & Amplifications
*In the original version of the post, r4 Technologies was used to exemplify an insight-driven data network effect. As this example was not entirely correct, another example is used in this version.